在基于MySQL传统复制的时代(MySQL版本低于5.5)MHA在MySQL高可用中可以说是独领风骚。在MySQL 5.6及GTID的出现后,MHA在这方面就显的不给力,和MHA作者交流,作者基本放弃该软件的维护,MHA作者现就职在Facebook,也没在使用MHA,他也认为在GTID环境下MHA存在的价值不大,不过你如果你还在使用传统复制,还是可以考虑使用MHA做主从的高可用(太老了,建议升级)。
下面我们围绕以下几点来讨论一下:
- 在MySQL 5.7 后为什么不需要MHA
- MySQL Plus 是什么,能解决什么问题
- MySQL Plus看他们如何搞定金融支持
MySQL 5.7后为什么不需要MHA
基于MySQL 5.7 GTID复制已经成熟,另外基于MySQL5.7的增强半同步性进一步提升: 所以在使用MySQL 5.7的复制可以使用: MySQL 5.7+GTID+增强半步, 在该结构中, 不存在会丢数据的问题。 所以MHA在这个结构基本失去了存在的意义。
但使用: MySQL 5.7+GTID+增强半步,也意为着新的知识,可能需要DBA同学们也要更新一下知识。而且在MySQL 5.7中引入binlog group commit, 又是对复制的一个加速。 所以说MySQL5.7 在复制完整性及性能上都有较大的提升,建议没升级的同学尽快升级了。
官方对MySQL 5.7的测试传送门: https://www.mysql.com/why-mysql/benchmarks/
MySQL Plus是什么,能解决什么问题
在3306π北京活动中 青云的蒙哲分享了青云RDS中高可用组件: MySQL Plus。 MySQL Plus是基于一套Raft构建的MySQL中自动选主及维护主从的套件,整体结构如下:
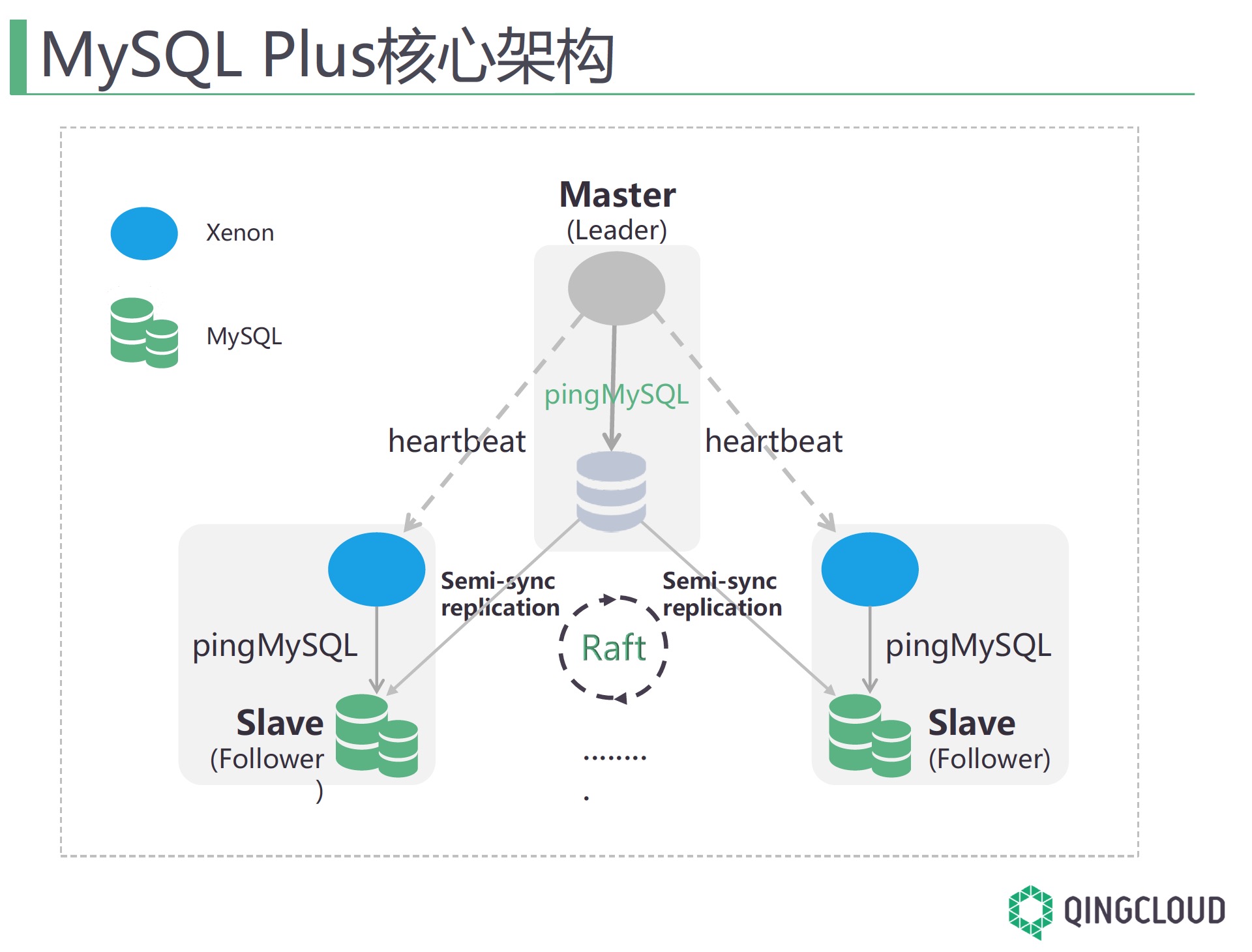
在该结构中Xenon之间会进行通信,在该结构中推荐三个节点的MySQL构建复制,听作者讲也支持两个节点的MySQL构建集群。
在MySQL Plus主要解决:
- 集群切换的强一致性(从上面架构看,更多的依赖于MySQL增强半同步,MySQL Plus在控制切换时,会做复制完成校验,从而且保证数据一致)
- 主从秒级别切换
- 无中心化自动选主
MySQL Plus看他们如何搞定金融环境
MySQL Plus 可以简单的理解是一个MySQL 5.7 GTID增强半同步复制的高可用管理组件。 在MySQL半同步配置方面,为了支持金融业务,青云给的配置如下:
- rpl_semi_sync_master_wait_no_slave=ON
- rpl_semi_sync_master_timeout=1000000000000000000
- rpl_semi_sync_master_wait_point=AFTER_SYNC
看到这个配置我才想明白为什么他们建议是三个节点,在rpl_semi_sync_master_timeout配置上可以说不允许退化到异步复制, 另外RadonDB负责人交流,在MySQL Plus架构中主节点上至少要求一个Slave给半同步应答。 所以2个节点对架构的稳定性也是一个保证。 另外在金融环境中,作者推荐所有请求都在主库上完成, 免的存在复制延迟造成交易数据异常。
在金融架构中,青云也提供一套基于MySQL Plus之上构建建的分库分表机制, 基于MySQL的事务强一致性约,在该平台支持OLTP和OLAP更感觉有点NewSQL的感觉。
下面是官方给的一个总结:

重大消息
如果想了解更多3306π是青云MySQL Plus PPT信息可以关注 3306pai公众号,回复“bj”获取 3306π北京的PPT打包下载。

MySQL Plus 官方要开源了,希望通过MySQL Plus给MySQL 5.7 GTID复制提供一个新的高可用方案。
更重大消息: QingCloud RDS : RadonDB也要开源了,大家期待一下吧。 如果感兴趣提前体验或是更多的关注 RadonDB发展,也可以加到QQ群:748415432 和群主及 RadonDB负责人直接对喊话。 技术在于相互沟通,你的建议也需是将来一个非常不错的功能。
作者:吴炳锡 来源:http://wubx.net/ 联系方式: wubingxi#163.com 转载请注明作/译者和出处,并且不能用于商业用途,违者必究.