在上课中讲到MySQL的binlog是mysql-bin.000001,有细心的学习提到,是不是这个达到mysql-bin.999999后数据库的binlog就要重新开始了?
对于这个问题一时间也被问住了,只是隐约记得这个可以出现大于999999,这次也来细致的研究一下,顺便Mark一下。
MySQL在启动时会扫一下binlog文件,找到sequence后最大的一个,然后产生下个文件,根据这个原理,我们可以先测试一下当有了mysql-bin.999999 后,数据库会不会产生mysql-bin.000001或是mysql-bin.1000000。
测试一:
把mysqld关掉,到日志目录:
touch mysql-bin.999999
[root@zst1 17:26:28 /data/mysql/mysql3307/logs]
#touch mysql-bin.999999
[root@zst1 17:26:37 /data/mysql/mysql3307/logs]
#ls -lh
total 12K
-rw-r----- 1 mysql mysql 923 May 22 22:16 mysql-bin.000001
-rw-r----- 1 mysql mysql 660 May 22 22:28 mysql-bin.000002
-rw-r--r-- 1 root root 0 May 24 17:26 mysql-bin.999999
-rw-r----- 1 mysql mysql 88 May 22 22:19 mysql-bin.index
[root@zst1 17:26:40 /data/mysql/mysql3307/logs]
#chown mysql:mysql *
[root@zst1 17:26:48 /data/mysql/mysql3307/logs]
#/usr/local/mysql/bin/mysqld --defaults-file=/data/mysql/mysql3307/my3307.cnf &
[root@zst1 17:27:17 /data/mysql/mysql3307/logs]
#ls -lh
total 76K
-rw-r----- 1 mysql mysql 923 May 22 22:16 mysql-bin.000001
-rw-r----- 1 mysql mysql 660 May 24 17:27 mysql-bin.000002
-rw-r----- 1 mysql mysql 194 May 24 17:27 mysql-bin.1000000
-rw-r--r-- 1 mysql mysql 0 May 24 17:26 mysql-bin.999999
-rw-r----- 1 mysql mysql 133 May 24 17:27 mysql-bin.index
启动mysqld
show master status 确认:
root@zhishutang:mysql3307.sock [(none)]>show master status;
+-------------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+------------------------------------------+
| mysql-bin.1000000 | 194 | | | 61beeb3d-2a88-11e7-9db9-080027f7e774:3-4 |
+-------------------+----------+--------------+------------------+------------------------------------------+
1 row in set (0.00 sec)
可以看到,并没有挂掉,也没重新从mysql-bin.000001开始。
对于这个问题,我们在来挖一下,具体是什么?
教学使用的版本是mysql-5.7.18下载相应的源码看看 : sql/binlog.cc 实际找到:
从这里可以看到:
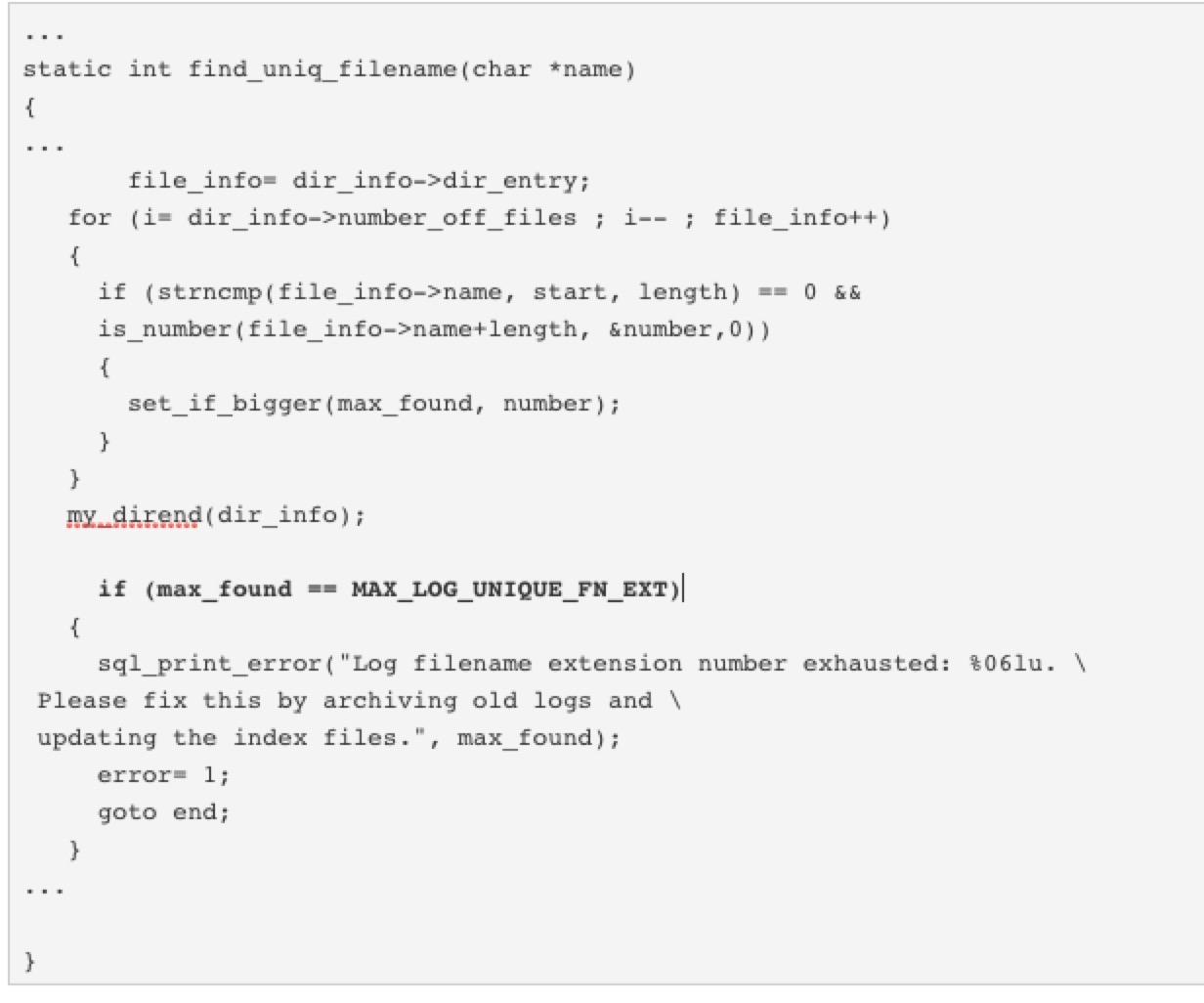
if (max_found == MAX_LOG_UNIQUE_FN_EXT)
当找到的数是定义的最大数时,就退出,再找一下MAX_LOG_UNIQUE_FN_EXT定义:
#define MAX_LOG_UNIQUE_FN_EXT 0x7FFFFFFF
root@zhishutang:mysql3307.sock [(none)]>select conv('7FFFFFFF',16,10);
+------------------------+
| conv('7FFFFFFF',16,10) |
+------------------------+
| 2147483647 |
+------------------------+
1 row in set (0.00 sec)
现在看到是最大值是: pow(2,31)-1
我们来测试几个场景:
测试二: 测试当达到mysql-bin.2147483647 再进行flush logs;MySQL的反应。
touch mysql-bin.2147483640
启动后给的警告:
2017-05-24T09:57:43.081308Z 0 [Warning] Next log extension: 2147483641. Remaining log filename extensions: 6. Please consider archiving some logs.
2017-05-24T09:57:43.081436Z 0 [Note] InnoDB: Buffer pool(s) load completed at 170524 17:57:43
2017-05-24T09:57:43.090250Z 0 [Warning] Next log extension: 2147483641. Remaining log filename extensions: 6. Please consider archiving some logs.
root@localhost:mysql3307.sock [(none)]>flush logs;
Query OK, 0 rows affected (0.01 sec)
root@localhost:mysql3307.sock [(none)]>show master status;
+----------------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+----------------------+----------+--------------+------------------+------------------------------------------+
| mysql-bin.2147483647 | 194 | | | 61beeb3d-2a88-11e7-9db9-080027f7e774:3-4 |
+----------------------+----------+--------------+------------------+------------------------------------------+
1 row in set (0.00 sec)
进行切换超限一下试试
root@localhost:mysql3307.sock [(none)]>flush logs;
ERROR 1598 (HY000): Binary logging not possible. Message: Either disk is full or file system is read only while rotating the binlog. Aborting the server.
root@localhost:mysql3307.sock [(none)]>flush logs;
ERROR 2006 (HY000): MySQL server has gone away
No connection. Trying to reconnect...
ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql3307.sock' (111)
ERROR:
Can't connect to the server
mysqld 直接退出…
报错日志:
2017-05-24T09:59:08.207040Z 3 [Warning] Next log extension: 2147483642. Remaining log filename extensions: 5. Please consider archiving some logs.
2017-05-24T09:59:09.970075Z 3 [Warning] Next log extension: 2147483643. Remaining log filename extensions: 4. Please consider archiving some logs.
2017-05-24T09:59:10.882140Z 3 [Warning] Next log extension: 2147483644. Remaining log filename extensions: 3. Please consider archiving some logs.
2017-05-24T09:59:12.050605Z 3 [Warning] Next log extension: 2147483645. Remaining log filename extensions: 2. Please consider archiving some logs.
2017-05-24T09:59:14.090312Z 3 [Warning] Next log extension: 2147483646. Remaining log filename extensions: 1. Please consider archiving some logs.
2017-05-24T09:59:26.483618Z 3 [Warning] Next log extension: 2147483647. Remaining log filename extensions: 0. Please consider archiving some logs.
2017-05-24T09:59:34.894426Z 3 [ERROR] Log filename extension number exhausted: 2147483647. Please fix this by archiving old logs and updating the index files.
2017-05-24T09:59:34.894441Z 3 [ERROR] Can't generate a unique log-filename /data/mysql/mysql3307/logs/mysql-bin.(1-999)
2017-05-24T09:59:34.894668Z 3 [ERROR] /usr/local/mysql/bin/mysqld: Binary logging not possible. Message: Either disk is full or file system is read only while rotating the binlog. Aborting the server.
看样是想产生mysql-bin.(1-999) 这样的文件。 再进行进行下面的测试。
测试三: 测试Binlog达到最大值后,能不能重新开始。
确保mysql-bin.000001不存在到999都不存在
root@localhost:mysql3307.sock [(none)]>show master status;
+----------------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+----------------------+----------+--------------+------------------+------------------------------------------+
| mysql-bin.2147483646 | 154 | | | 61beeb3d-2a88-11e7-9db9-080027f7e774:3-4 |
+----------------------+----------+--------------+------------------+------------------------------------------+
1 row in set (0.00 sec)
root@localhost:mysql3307.sock [(none)]>flush logs;
Query OK, 0 rows affected (0.01 sec)
root@localhost:mysql3307.sock [(none)]>show master status;
+----------------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+----------------------+----------+--------------+------------------+------------------------------------------+
| mysql-bin.2147483647 | 154 | | | 61beeb3d-2a88-11e7-9db9-080027f7e774:3-4 |
+----------------------+----------+--------------+------------------+------------------------------------------+
1 row in set (0.00 sec)
root@localhost:mysql3307.sock [(none)]>flush logs;
ERROR 1598 (HY000): Binary logging not possible. Message: Either disk is full or file system is read only while rotating the binlog. Aborting the server.
root@localhost:mysql3307.sock [(none)]>show master status;
ERROR 2006 (HY000): MySQL server has gone away
No connection. Trying to reconnect...
ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql3307.sock' (111)
ERROR:
Can't connect to the server
一样退出。并没有进行日志的轮换使用。
结论:
1. mysql binlog的最大sequence是:pow(2,31)-1 = 2147483647
2. 当binlog接近这个值是小于1000开始向error log中写入警告
3. binlog的sequence达到最大值时,不管有没有mysql-bin.000001类似这样的文件,mysqld都是退出。
4. 在mysql产生binlog时会读取当前日件文目录下的log-bin的base name获取下一个日志文件的后面的Seq。 所以日志目录下文件太多,会影响MySQL的启动及日志切换。 这里也有一个大的隐患运行中给放一个较大的日志文件,在下次日志文件切换时有可能很快就接近于最大值,造成mysqld crash退出。
5. 一定要监控error log的输出。并足够重视。
作者:吴炳锡 来源:http://wubx.net/ 联系方式: wubingxi#163.com 转载请注明作/译者和出处,并且不能用于商业用途,违者必究.