SeaTunnel MySQL-CDC Research

SeaTunnel 是一个非常易用、超高性能的分布式数据集成平台,支持实时海量数据同步。 每天可稳定高效地同步数百亿数据,已被近百家企业应用于生产,在国内较为普及。
Databend 是一款云原生存算分离的数据平台。
本文主要分析 SeaTunnel MySQL-CDC 及其 Sink 输出的数据格式,并探讨两者后续和 Databend 整合的可行性。
SeaTunnel 整体是一个标准的数据同步工具:
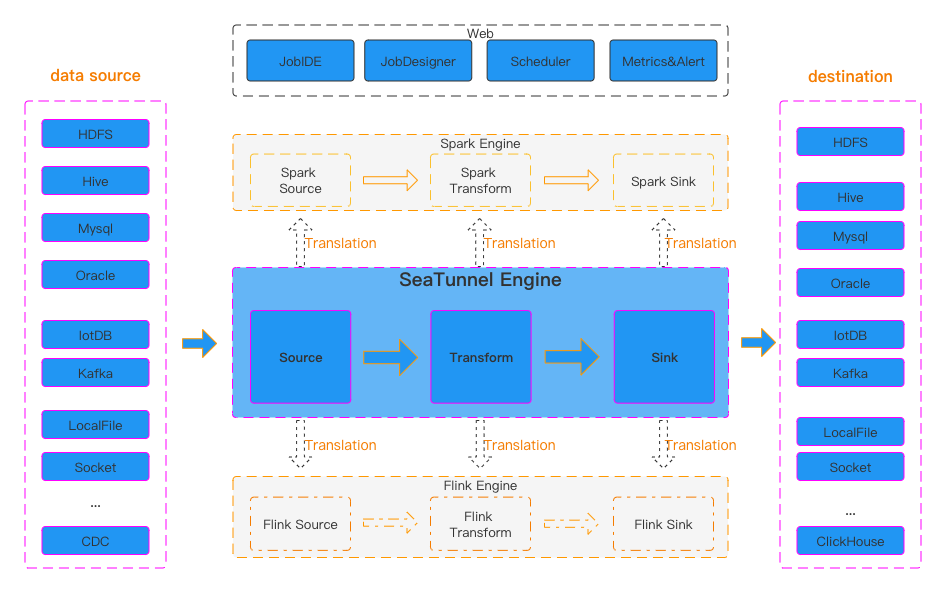
SeaTunnel 和 MySQL-CDC
SeaTunnel 的 MySQL CDC 连接器允许从 MySQL 数据库中读取快照数据和增量数据。根据不同的 sink 端,观察 MySQL-CDC 输出的数据是否可以直接被 Databend 使用。 从测试来看,SeaTunnel 所用的 MySQL 同步组件应该是 debezium-mysql-connector(Kafka Connect 也调用该组件)。
source: MySQL-CDC sink: console
任务设定是通过 SeaTunnel 从 MySQL 中同步 wubx.t01 表。 配置文件 v2.mysql.streaming.conf
# v2.mysql.streaming.conf
env{
parallelism = 1
job.mode = "STREAMING"
checkpoint.interval = 2000
}
source {
MySQL-CDC {
base-url="jdbc:mysql://192.168.1.100:3306/wubx"
username="wubx"
password="wubxwubx"
table-names=["wubx.t01"]
startup.mode="initial"
}
}
sink {
Console {
}
}
启动 SeaTunnel
./bin/seatunnel.sh --config ./config/v2.mysql.streaming.conf -m local
观察终端上日志
观察到全量同步
SELECT * FROM `wubx`.`t01`
获取到的数据如下:
2025-05-07 14:28:21,914 INFO [.a.s.c.s.c.s.ConsoleSinkWriter] [st-multi-table-sink-writer-1] - subtaskIndex=0 rowIndex=1: SeaTunnelRow#tableId=wubx.t01 SeaTunnelRow#kind=INSERT : 1, databend
2025-05-07 14:28:21,914 INFO [.a.s.c.s.c.s.ConsoleSinkWriter] [st-multi-table-sink-writer-1] - subtaskIndex=0 rowIndex=2: SeaTunnelRow#tableId=wubx.t01 SeaTunnelRow#kind=INSERT : 3, MySQL
2025-05-07 14:28:21,914 INFO [.a.s.c.s.c.s.ConsoleSinkWriter] [st-multi-table-sink-writer-1] - subtaskIndex=0 rowIndex=3: SeaTunnelRow#tableId=wubx.t01 SeaTunnelRow#kind=INSERT : 4, Setunnel01
全量同步完成
source 端 insert
insert into t01 values(5,'SeaTunnel'); 在 SeaTunnel 中可以直接捕获到增量数据,对应的动作为 kind=INSERT。
2025-05-07 14:35:48,520 INFO [.a.s.c.s.c.s.ConsoleSinkWriter] [st-multi-table-sink-writer-1] - subtaskIndex=0 rowIndex=4: SeaTunnelRow#tableId=wubx.t01 SeaTunnelRow#kind=INSERT : 5, SeaTunnel
source 端 update
update t01 set c1='MySQL-CDC' where id=5;
2025-05-07 14:36:47,455 INFO [.a.s.c.s.c.s.ConsoleSinkWriter] [st-multi-table-sink-writer-1] - subtaskIndex=0 rowIndex=5: SeaTunnelRow#tableId=wubx.t01 SeaTunnelRow#kind=UPDATE_BEFORE : 5, SeaTunnel
2025-05-07 14:36:47,455 INFO [.a.s.c.s.c.s.ConsoleSinkWriter] [st-multi-table-sink-writer-1] - subtaskIndex=0 rowIndex=6: SeaTunnelRow#tableId=wubx.t01 SeaTunnelRow#kind=UPDATE_AFTER : 5, MySQL-CDC
source 端 delete
delete from t01 where id=5;
2025-05-07 14:37:33,082 INFO [.a.s.c.s.c.s.ConsoleSinkWriter] [st-multi-table-sink-writer-1] - subtaskIndex=0 rowIndex=7: SeaTunnelRow#tableId=wubx.t01 SeaTunnelRow#kind=DELETE : 5, MySQL-CDC
从 console 输出的日志格式较为清晰,非常利于排查问题和后续使用。
source: MySQL-CDC sink: MySQL
通过上述 MySQL-CDC 输出终端的测试,可以确认 insert、update、delete 操作均能被正确捕获和处理。接下来我们测试 MySQL-CDC -> MySQL,对应的配置文件 v2.mysql.streaming.m.conf 如下:
#v2.mysql.streaming.m.conf
env{
parallelism = 1
job.mode = "STREAMING"
checkpoint.interval = 2000
}
source {
MySQL-CDC {
base-url="jdbc:mysql://192.168.1.100:3306/wubx"
username="wubx"
password="wubxwubx"
table-names=["wubx.t01"]
startup.mode="initial"
}
}
sink {
jdbc {
url = "jdbc:mysql://192.168.1.100:3306/wubx?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"
driver = "com.mysql.cj.jdbc.Driver"
user = "wubx"
password = "wubxwubx"
generate_sink_sql = true
# You need to configure both database and table
database = wubx
table = s_t01
primary_keys = ["id"]
schema_save_mode = "CREATE_SCHEMA_WHEN_NOT_EXIST"
data_save_mode="APPEND_DATA"
}
}
启动 SeaTunnel
./bin/seatunnel.sh --config ./config/v2.mysql.streaming.m.conf -m local
观察终端上日志
同步过程分析
全量同步语句:
2025-05-07 14:56:01,024 INFO [e.IncrementalSourceScanFetcher] [debezium-snapshot-reader-0] - Start snapshot read task for snapshot split: SnapshotSplit(tableId=wubx.t01, splitKeyType=ROW<id INT>, splitStart=null, splitEnd=null, lowWatermark=null, highWatermark=null) exactly-once: false
2025-05-07 14:56:01,026 INFO [f.s.MySqlSnapshotSplitReadTask] [debezium-snapshot-reader-0] - Snapshot step 1 - Determining low watermark {ts_sec=0, file=mysql-bin.000058, pos=7737, gtids=12b437c2-ba62-11ec-a554-b4b5b694bca5:1-2215900, row=0, event=0} for split SnapshotSplit(tableId=wubx.t01, splitKeyType=ROW<id INT>, splitStart=null, splitEnd=null, lowWatermark=null, highWatermark=null)
2025-05-07 14:56:01,028 INFO [f.s.MySqlSnapshotSplitReadTask] [debezium-snapshot-reader-0] - Snapshot step 2 - Snapshotting data
2025-05-07 14:56:01,028 INFO [f.s.MySqlSnapshotSplitReadTask] [debezium-snapshot-reader-0] - Exporting data from split 'wubx.t01:0' of table wubx.t01
2025-05-07 14:56:01,028 INFO [f.s.MySqlSnapshotSplitReadTask] [debezium-snapshot-reader-0] - For split 'wubx.t01:0' of table wubx.t01 using select statement: 'SELECT * FROM `wubx`.`t01`'
2025-05-07 14:56:01,032 INFO [f.s.MySqlSnapshotSplitReadTask] [debezium-snapshot-reader-0] - Finished exporting 3 records for split 'wubx.t01:0', total duration '00:00:00.004'
2025-05-07 14:56:01,033 INFO [f.s.MySqlSnapshotSplitReadTask] [debezium-snapshot-reader-0] - Snapshot step 3 - Determining high watermark {ts_sec=0, file=mysql-bin.000058, pos=7737, gtids=12b437c2-ba62-11ec-a554-b4b5b694bca5:1-2215900, row=0, event=0} for split SnapshotSplit(tableId=wubx.t01, splitKeyType=ROW<id INT>, splitStart=null, splitEnd=null, lowWatermark=null, highWatermark=null)
2025-05-07 14:56:01,519 INFO [o.a.s.c.s.c.s.r.f.SplitFetcher] [Source Data Fetcher for BlockingWorker-TaskGroupLocation{jobId=972391330309210113, pipelineId=1, taskGroupId=2}] - Finished reading from splits [wubx.t01:0]
sink 端写数据对应的 prepare 语句
2025-05-07 14:56:01,708 INFO [.e.FieldNamedPreparedStatement] [st-multi-table-sink-writer-1] - PrepareStatement sql is:
INSERT INTO `wubx`.`s_t01` (`id`, `c1`) VALUES (?, ?) ON DUPLICATE KEY UPDATE `id`=VALUES(`id`), `c1`=VALUES(`c1`)
2025-05-07 14:56:01,709 INFO [.e.FieldNamedPreparedStatement] [st-multi-table-sink-writer-1] - PrepareStatement sql is:
DELETE FROM `wubx`.`s_t01` WHERE `id` = ?
从上述语句可以看出,对应的 binlog event 可以直接处理:
- insert ,update 可以直接用 INSERT INTO
wubx.s_t01(id,c1) VALUES (?, ?) ON DUPLICATE KEY UPDATEid=VALUES(id),c1=VALUES(c1) 处理 - delete 使用: DELETE FROM
wubx.s_t01WHEREid= ? 处理
小结
SeaTunnel MySQL-CDC 这块应该比较稳定,底层数据读取使用的是 debezium,这是一个非常成熟的工具,值得信赖。
source: MySQL-CDC sink: s3 format json
本节也重点关注在云环境下的数据同步基座,尤其是如何以最低成本完成数据同步工作。在云上进行数据同步时,需要考虑如何以最低成本完成这项工作。在海外项目中,开发者更倾向于使用 kafka-connect,通常先将数据 Sink 到 S3 中,然后批量处理 S3 中的文件,最终得到一份完整的数据。
直接使用配置文件 v2.mysql.streaming.s3.conf:
env{
parallelism = 1
job.mode = "STREAMING"
checkpoint.interval = 2000
}
source {
MySQL-CDC {
base-url="jdbc:mysql://192.168.1.100:3306/wubx"
username="wubx"
password="wubxwubx"
table-names=["wubx.t01"]
startup.mode="initial"
}
}
sink {
S3File {
bucket = "s3a://mystage"
tmp_path = "/tmp/SeaTunnel/${table_name}"
path="/mysql/${table_name}"
fs.s3a.endpoint="http://192.168.1.100:9900"
fs.s3a.aws.credentials.provider="org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider"
access_key = "minioadmin"
secret_key = "minioadmin"
file_format_type="json"
schema_save_mode = "CREATE_SCHEMA_WHEN_NOT_EXIST"
data_save_mode="APPEND_DATA"
}
}
首先使用 json 格式进行 sink
启动 SeaTunnel
./bin/seatunnel.sh --config ./config/v2.mysql.streaming.s3.conf -m local
观察终端上日志
发现全量同步
2025-05-07 15:14:41,430 INFO [.c.s.f.h.HadoopFileSystemProxy] [hz.main.generic-operation.thread-42] - rename file :[/tmp/SeaTunnel/t01/SeaTunnel/972396021571125249/c679929b12/T_972396021571125249_c679929b12_0_1/NON_PARTITION/T_972396021571125249_c679929b12_0_1_0.json] to [/mysql/t01/T_972396021571125249_c679929b12_0_1_0.json] finish
/mysql/t01/T_972396021571125249_c679929b12_0_1_0.json 内容:
{"id":1,"c1":"databend"}
{"id":3,"c1":"MySQL"}
{"id":4,"c1":"Setunnel01"}
{"id":5,"c1":"SeaTunnel"}
看到这里感觉有些失望,似乎缺少了 kind 和时间字段。
source 端 insert
接下来 insert into t01 values(6,'SeaTunnel01');
2025-05-07 15:18:59,380 INFO [.c.s.f.h.HadoopFileSystemProxy] [hz.main.generic-operation.thread-16] - rename file :[/tmp/SeaTunnel/t01/SeaTunnel/972396021571125249/c679929b12/T_972396021571125249_c679929b12_0_130/NON_PARTITION/T_972396021571125249_c679929b12_0_130_0.json] to [/mysql/t01/T_972396021571125249_c679929b12_0_130_0.json] finish
T_972396021571125249_c679929b12_0_130_0.json 内容为:
{"id":6,"c1":"SeaTunnel01"}
source 端 update
update t01 set c1='MySQL-CDC' where id=5;
2025-05-07 15:20:15,386 INFO [.c.s.f.h.HadoopFileSystemProxy] [hz.main.generic-operation.thread-9] - rename file :[/tmp/SeaTunnel/t01/SeaTunnel/972396021571125249/c679929b12/T_972396021571125249_c679929b12_0_168/NON_PARTITION/T_972396021571125249_c679929b12_0_168_0.json] to [/mysql/t01/T_972396021571125249_c679929b12_0_168_0.json] finish
T_972396021571125249_c679929b12_0_168_0.json 对应内容:
{"id":5,"c1":"SeaTunnel"}
{"id":5,"c1":"MySQL-CDC"}
一个 update 操作在 json 文件中记录了两条数据,但由于缺少操作类型(kind)和时间字段,难以准确还原数据变更过程。如果包含时间字段,还可以选择保留最新的一条记录。
source 端 delete
delete from t01 where id=5;
2025-05-07 15:22:53,392 INFO [.c.s.f.h.HadoopFileSystemProxy] [hz.main.generic-operation.thread-6] - rename file :[/tmp/SeaTunnel/t01/SeaTunnel/972396021571125249/c679929b12/T_972396021571125249_c679929b12_0_247/NON_PARTITION/T_972396021571125249_c679929b12_0_247_0.json] to [/mysql/t01/T_972396021571125249_c679929b12_0_247_0.json] finish
T_972396021571125249_c679929b12_0_247_0.json 对应的内容
{"id":5,"c1":"MySQL-CDC"}
delete 操作同样缺少操作类型(kind),仅记录了一行原始数据,因此难以用于后续的数据处理和溯源。
小结
因此,利用 SeaTunnel 的 S3File sink 以 json 格式进行数据溯源目前并不可行。建议 S3File sink 增加对 maxwell_json 和 debezium_json 格式的支持。
期待这一功能的完善,这样 SeaTunnel 就可以将所有数据同步到 S3,让 S3 承担消息队列的功能。
source: MySQL-CDC sink: Kafka
开源世界非常有趣,如果一个功能无法实现,总会有其他替代方案。 因为 MySQL-CDC 底层基于 Debezium,应该支持 Debezium format。
https://SeaTunnel.apache.org/docs/2.3.10/connector-v2/formats/debezium-json 而且还支持 https://SeaTunnel.apache.org/docs/2.3.10/connector-v2/formats/maxwell-json
也就是说,SeaTunnel 为了保持与 debezium 和 maxwell 的兼容性,支持在 sink 到 Kafka 时选择这两种格式。
debezium-json
{
"before": {
"id": 111,
"name": "scooter",
"description": "Big 2-wheel scooter ",
"weight": 5.18
},
"after": {
"id": 111,
"name": "scooter",
"description": "Big 2-wheel scooter ",
"weight": 5.17
},
"source": {
"version": "1.1.1.Final",
"connector": "mysql",
"name": "dbserver1",
"ts_ms": 1589362330000,
"snapshot": "false",
"db": "inventory",
"table": "products",
"server_id": 223344,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 2090,
"row": 0,
"thread": 2,
"query": null
},
"op": "u",
"ts_ms": 1589362330904,
"transaction": null
}
上述格式的数据在 Databend 或 Snowflake 中都比较容易处理,可以根据对应的
"op": "u",
"ts_ms": 1589362330904,
使用 merge into + stream 的方式把数据合并到目标表中。
maxwell-json
{
"database":"test",
"table":"product",
"type":"insert",
"ts":1596684904,
"xid":7201,
"commit":true,
"data":{
"id":111,
"name":"scooter",
"description":"Big 2-wheel scooter ",
"weight":5.18
},
"primary_key_columns":[
"id"
]
}
这个 json 体中包含了 type、ts 和主键字段,后续利用 SQL 进行 ELT 处理也非常方便。
小结
也就是说,如果想用 SeaTunnel 输出这种标准的 CDC 格式日志,还需要引入类似 Kafka 的架构:
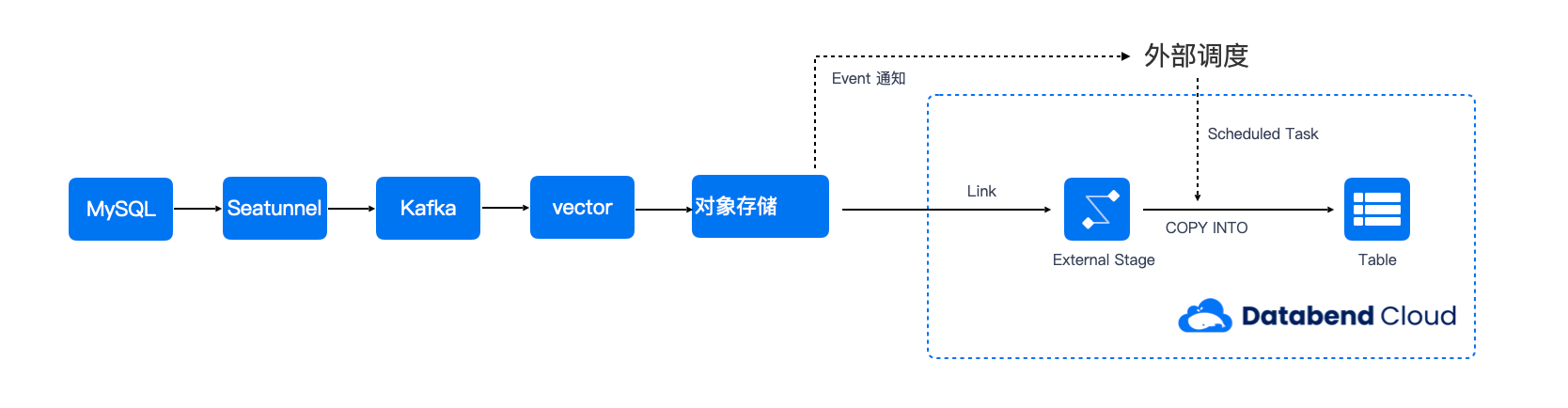 与群里的小伙伴交流后发现,确实有人这么做,从 Kafka 中将消息同步到 OSS 上。
与群里的小伙伴交流后发现,确实有人这么做,从 Kafka 中将消息同步到 OSS 上。
用 maxwell-json 消息体举例实现和 Databend 的整合
- 创建一个用于记录 binlog 消息体明细的 update 表,用于记录明细
create table t01_update(
database varchar,
table varchar,
type varchar,
ts bigint,
xid bigint,
commit boolean,
data variant,
primary_key_columns array(varchar)
);
该表数据源可以从 S3 获取,利用 copy into 可以把对应的数据近实时的加载到 t01_update 这张表里
- 创建一个目标表: t01
create table t01(
id int,
name varchar,
description varchar,
weight double
);
- 对 t01_update 表创建一个 stream 用于记录该表的增量
create stream stream_t01_update on table t01_update;
- 在 Databend 实现该数据合并到目标表中
MERGE INTO t01 AS a
USING (
SELECT
data:id AS id,
data:name AS name,
data:description AS description,
data:weight AS weight,
ts,
type
FROM stream_t01_update
QUALIFY ROW_NUMBER() OVER (PARTITION BY id ORDER BY ts DESC) = 1
) AS b
ON a.id = b.id
WHEN MATCHED AND b.type = 'update' THEN
UPDATE SET
a.name = b.name,
a.description = b.description,
a.weight = b.weight
WHEN MATCHED AND b.type = 'delete' THEN
DELETE
WHEN NOT MATCHED THEN
INSERT (id, name, description, weight)
VALUES (b.id, b.name, b.description, b.weight);
通过该 SQL,可以实现以窗口去重的方式,将 binlog 原始数据合并到目标表。
SeaTunnel 和 Databend 整合思路
通过对 MySQL-CDC 输出形态的分析,目前有三种方案可以实现 SeaTunnel 和 Databend 的整合:
- 第一种方式是直接开发 Databend 的 SeaTunnel connector,支持 sink 和 source。这种方式实现简单
- 第二种方式是在 S3File 中增加对 debezium-json 和 maxwell-json 格式的支持,这是一种较为优雅的方案,后续增量数据可以基于 Databend Stream 提供,方便外部数据源直接获取
- 第三种方式是引入 Kafka 作为 SeaTunnel 的 Sink,这样可以直接使用 debezium-json 和 maxwell-json 格式的消息体,通过数据治理实现 MySQL-CDC 到 Databend 的同步。这种方式方便多个下游系统订阅 Kafka 中的增量数据。
通过对 SeaTunnel 多种格式输出及行为的测试,初步了解了 SeaTunnel MySQL-CDC 的能力,为后续与 Databend 的整合做了准备。SeaTunnel 结合 Spark、Flink 等生态,已经可以胜任大型 CDC 任务。如果有相关实践,欢迎与作者交流分享。
💬 社区支持
有问题与我们的团队联系:Slack微信:82565387
