使用 Databend Cloud 归档 OceanBase 数据数据库

数据归档: 随着生产数据库数据量增大,对于备份和性能都带来比较严重的影响,可以通过归档的方案,可以将主库中早期不使用的数据,如早期订单或日志移动到归档库中。减少生产数据库的数据大小,提升生产数据库的性能。 数据归档是生产数据中面临的一个重要工作,在本篇文章中使用 Databend Cloud 归档 OceanBase, 同理也适用于: MySQL, TiDB, PostgreSQL, Oracle, SQL Server 等。 使用工具: db-archiver 数据存储: 用户端的 bucket 中 计算资源: Databend Cloud 按需付费
1. 整体架构图
本次 Demo 以阿里云为基础:
 上图描述:
上图描述:
- 使用 db-archiver 连接 OceanBase 读取数据写入 Databend Cloud 中
- Databend Cloud 使用外部表把数据存储在用户的 Bucket 中
- Databend Cloud 在不使用时没有任何费用,使用时直接通过 Databend Cloud 平台访问,大大简化使用和运维操作。
接下来内容我们来演示一下上面的操作
2. 环境准备
- 下载 db-archiver: https://github.com/databendcloud/db-archiver/releases
- 注册 Databend Cloud https://app.databend.cn/ (添加文末的微信获得更多支持)
- 准备要存储数据的 bucket 及对应的 ak/sk 信息和连接串信息
2.1 下载 db-archiver
db-archiver 是基于 Golang 开发, 如果能力也可以基于 main 编译,这样发现不爽的地方,可以直接修改,但做作为使用者我一般是偷懒主义下载可用的二进制版本, 注意
- linux-amd64 对应 64 位 X86 CPU
- linux-arm64 对应 64 位的 ARM CPU 下载解压后只有一个 db-archiver 执行程序,对于配置文件,可以参考: https://docs.databend.com/tutorials/migrate/migrating-from-mysql-with-db-archiver
#cat jobs/20250716/ob-sbtest1-lt2000w-to-databend/ob-sbtest1-lt2000w-to-databendcloud.json
{
"sourceHost": "192.168.1.207",
"sourcePort": 2883,
"sourceUser": "root",
"sourcePass": "OB密码",
"sourceDB": "wubx",
"sourceTable":"sbtest1",
"sourceQuery": "select * from wubx.sbtest1",
"sourceWhereCondition": "id <= 20000000",
"sourceSplitKey": "id",
"databendDSN": "https://wubx:password@租户名.gw.aliyun-cn-beijing.default.databend.cn/wubx?warehouse=small-wubx",
"databendTable": "wubx.sbtest1",
"batchSize": 20000,
"batchMaxInterval": 30,
"maxThread": 5,
"deleteAfterSync": false
}
上述配置文件简要说明
- sourceHost 源端 IP
- sourcePort 源端 port
- sourceUser 源端用户名
- sourcePass 源端密码
- sourceDB 源端 DB
- sourceTable 源端要迁移的 Table
- sourceQuery 归档读取数据的 SQL ,可以指定列
- sourceWhereCondition 归档条件, 数据过滤的条件可以写在这里
- sourceSplitKey 归档任务数据区间拆分的 key
- databendDSN 写入 Databend Cloud 的连接地址
- databendTable 写入的 Table
- batchSize 读取和写入的每个 Batch 多大
- batchMaxInterval 一个 Batch 最大间隔时间,用于对源库做一个保护,单位 秒
- maxThread 归档任务数
- deleteAfterSync 归档成功后是否会删除源端数据
db-archiver 限制, 目前 db-archiver 归档对源表要求:
- 有整数的主键
- sourceWhereCondition 基于任务拆分键的条件
- sourceSplitKey 任务拆分键
- 或是有基于明确的时间列做归档
- sourceWhereCondition 基于时间过滤的条件
- sourceSplitTimeKey 时间字段
- timeSplitUnit 任务切分的单位
任务的 json 文件后续可以考虑用工具生成,这样就方便集成 db-archiver
这里提供一个基于时间归档的配置:
{
"sourceHost": "127.0.0.1",
"sourcePort": 3306,
"sourceUser": "root",
"sourcePass": "12345678",
"sourceDB": "mydb",
"sourceTable": "test_table1",
"sourceQuery": "select * from mydb.test_table1",
"sourceWhereCondition": "t1 >= '2024-06-01' and t1 < '2024-07-01'" and status=1,
"sourceSplitTimeKey": "t1",
"timeSplitUnit": "hour",
"databendDSN": "https://cloudapp:password@tn3ftqihs--medium-p8at.gw.aws-us-east-2.default.databend.com:443",
"databendTable": "default.test_table1",
"batchSize": 10000,
"batchMaxInterval": 30,
"copyPurge": true,
"copyForce": false,
"disableVariantCheck": true,
"userStage": "~",
"deleteAfterSync": false,
"maxThread": 10
}
2.2 注册 Databend Cloud
注册完 Databend Cloud 需要创建归档的用的 DB 及对应的表,获取连接 Databend Cloud 的连接。
2.2.1 创建DB及外部表
 创建 DB 并使用
创建 DB 并使用
create database wubx;
use wubx;
创建连接名称对应的存储(bucket),需要提前准备好存储的连接 URL 和对应的 AK/SK 信息:
CREATE or replace CONNECTION wubx_oss
STORAGE_TYPE = 'oss'
ENDPOINT_URL='oss-cn-beijing-internal.aliyuncs.com'
ACCESS_KEY_ID = '替换用户 AK'
access_key_secret = '替换用户 SK';
创建外部表,需要准备好用户名准备的 bucket 名,及在 bucket 下存放的 prefix
CREATE TABLE sbtest1 (
id int(11) NOT NULL,
k int(11) NOT NULL DEFAULT '0',
c char(120) NOT NULL DEFAULT '',
pad char(60) NOT NULL DEFAULT ''
)
'oss://wubx-bj01/wubx/'
connection=(
connection_name='wubx_oss'
);
例如 sbtest1 存储在在 oss://wubx-bj/wubx/ 下面。
表结构一般是删除源库中的索引后,直接在 Databend 中创建。不过,创建外部表时,需注意指定连接信息。 表结构转换也可以使用: https://github.com/wubx/databend-workshop/blob/main/datax_mysql2databend/mysql_str2databend.py 这个脚本自动转换
2.3 获取连接 Databend Cloud 信息
创建一个连接 Databend Cloud 使用用的程序用的用户名和密码
create role wubx_admin;
grant ownership on wubx.* to role wubx_admin;
create user 'wubx' identified by 'password';
grant role wubx_admin to wubx;
alter user wubx with default_role='wubx_admin';
通过 Role 来控制权限,方便后期做权限规划
获取连接串
首页概览::连接(DSN)
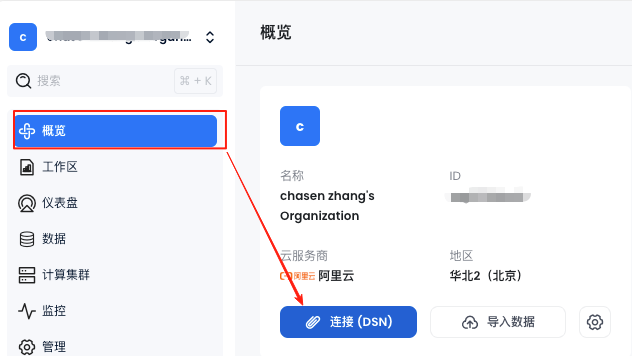 在这个里面选择使用的数据库和计算集群,对于归档来讲,创建一个 xsmall 的集群即可,如果将来不够用了,可以创建 multi-cluster 的集群。主要关注一下主机连接串
在这个里面选择使用的数据库和计算集群,对于归档来讲,创建一个 xsmall 的集群即可,如果将来不够用了,可以创建 multi-cluster 的集群。主要关注一下主机连接串
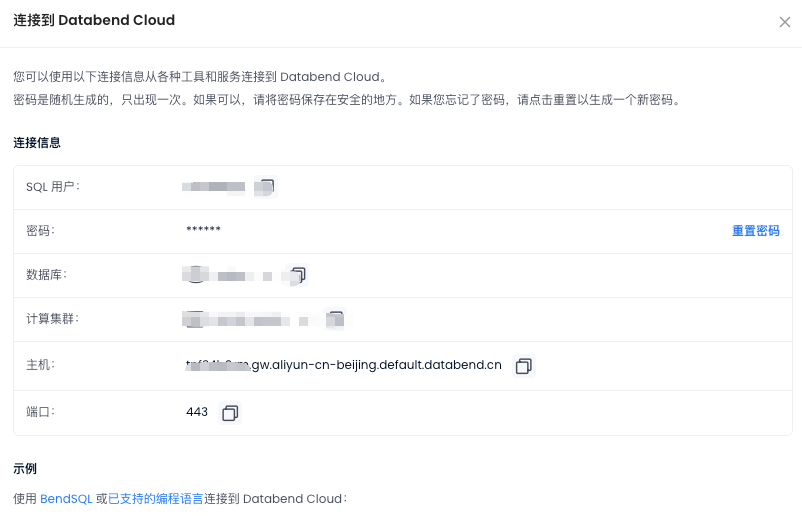
例如这里获取的为: 租户名.gw.aliyun-cn-beijing.default.databend.cn 补全一个 DSN 为: https://wubx:password@租户名.gw.aliyun-cn-beijing.default.databend.cn/wubx?warehouse=small-wubx
参考格式: https://用户名:密码@租户名.gw.aliyun-cn-beijing.default.databend.cn/数据库名?warehouse=集群名
也可以直接使用平台上 cloudapp 这个用户生成的连接。
其它注意事项:
使用 bendsql 连接 Databend Cloud 有两种方式:
1. 使用 DSN 方式,也是推荐的方式: https://docs.databend.cn/tutorials/connect/connect-to-databendcloud-bendsql
export databend://用户名:密码@租户名.gw.aliyun-cn-beijing.default.databend.cn:443/wubx?warehouse=small-wubx
bendsql
2. 使用命令行参数:
bendsql -h 租户名.gw.aliyun-cn-beijing.default.databend.cn -P 443 --tls true -u 用户名 -p 密码 --set warehouse=small-wubx
3. 数据归档
./db-archiver -f ./jobs/20250716/ob-sbtest1-lt2000w-to-databend/ob-sbtest1-lt2000w-to-databendcloud.json >> ./jobs/20250716/ob-sbtest1-lt2000w-to-databend/ob-sbtest1-lt2000w-to-databendcloud.log 2>&1
把任务生成的 log 直接存到对应的目录下面,后面方便分析。 任务运行完会提示源库多少条,目标同步完成多少条,也可以在 Databend Cloud 平台直接查询。另外一些报表任务也可以在 Databend Cloud 中体验一下。
4. 总结
该方法的优点:
- 完全利用云上基础设施可以实现按需付费。 存储的按需储费, 计算 Databend Cloud 按需付费。
- 基于无运维操作,算力可以根据需求秒级伸缩
- 合理的调整数据摄入接点休眠时间,来节省费用
💬 社区支持
有问题与我们的团队联系:Slack微信:82565387
